

浅谈 PostgreSQL 动态哈希表

文一
只有勤下功夫,多做总结,才可以成为一流的 PostgreSQL 内核研究者,目前国内 PostgreSQL 内核相关的材料依旧十分稀缺,我们呼吁更多的人参与到内核研究之中,共同建设一个繁荣的 PostgreSQL 生态。
在 PostgreSQL 中,动态哈希表模块的应用场景非常丰富,可谓是内核模块中的重中之重,我们可以通过下面图中所展现出来的信息,窥见其重要性:
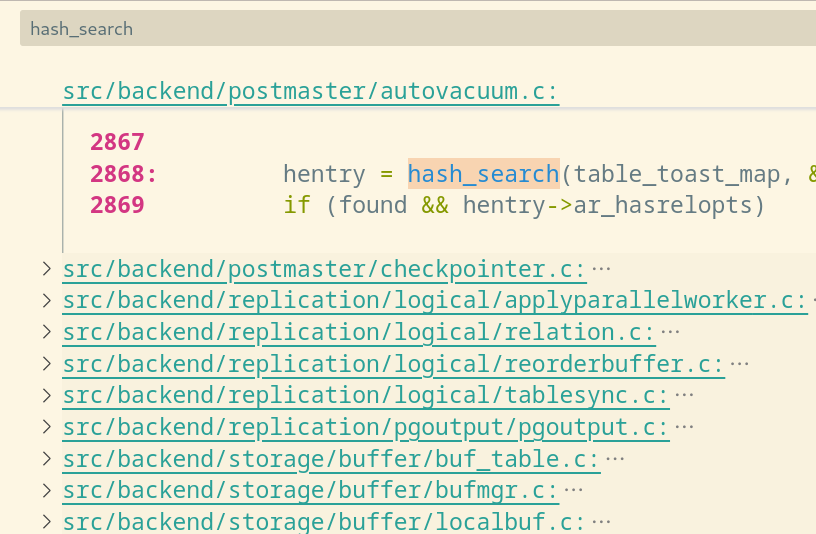
(在 VSCODE 中可以尝试在 PostgreSQL 源代码目录内以 `hash_search` 为关键字(这是动态哈希表模块的一个标志性函数)搜索动态哈希表模块在各个组件中的应用,可以看到,许多的重要组件,如逻辑复制功能,存储缓冲区模块,系统缓存模块,GUC模块等,都有他们的身影)
而动态哈希表本身的实现代码,则位于 `src/backend/utils/hash/dynahash.c` 和 `src/include/utils/dynahash.h` 中,参考如下:
而想要理解其实现,则需要对如下的前置知识点,建立基本的了解(之前我在既没有阅读对应文章,也没有理顺缓存系统和动态哈希模块的情况下直接分析了对应的内核源代码,吃了很大的亏,走了不少弯路)。
## 设计原理:源自于《Dynamic Hash Tables》的思考
哈希表作为一种经典的数据结构,源自于20世纪80年代业界对于文件系统存储数据结构的研究(B树同样是那个时期所诞生出来的重要研究成果),它可以帮助我们在一个大体恒定的时间上,高效地展开文件的搜索工作。
原理参见下图:

而论文《Dynamic Hash Tables》所展开的研究性工作,其主要的成果在于,一方面,将本来应用于外部文件系统的哈希表数据结构,成功拓展应用于内存中的大量小数据块的快速读写;另一方面,顺利探索出一种有效拓展哈希表容量的办法,降低了数据重分布的成本。
什么是重分布?
哈希函数的计算,最终都需要将数据存储的位置,落地于哈希表表内。
而受限于哈希表的存储容量,加之哈希函数自身的计算范围有限性,不同数据得出同一存储位置的可能性总是客观存在(这种情况叫做碰撞)。
举例而言,假如我们的哈希表只能存储10个元素,但是,我们却试图在哈希表内加入20个不同的元素,那么,无论如何,哈希函数都会计算出10个“不同数据相同位置”的结果,而这种情况假若我们不加处理,势必造成困扰,干扰正常工作的进行。
而想要解决这种“碰撞”,我们可以:
1. 拓展哈希表的容量,让其可以存储更多的元素
2. 为每一个元素设立更多的标识信息,确保在哈希值之外,可以将他们区分开来
3. 找到更好的哈希函数,降低因为哈希函数自身原因引发碰撞的可能性

(本质上都是用更大的空间降低碰撞的可能性)
而重分布,往往发生于横向拓展即直观拓展哈希表容量的场景下,因为参与哈希函数计算的数据表容量的参数发生了变化,因此采用旧容量计算下的,分布于哈希表各处的数据也需要迁移到新容量计算下的新位置上,而因为这项操作涉及到整个表既有的全部元素,因此成本非常高昂,需要我们想办法去避免重分布的发生。

(《Dynamic Hash Table》论文的摘要篇章中的一部分,即对于作者研究成果的介绍)
而《Dynamic Hash Table》降低数据重分布成本的办法,也非常简单,这里我们直接援引论文中的插图:
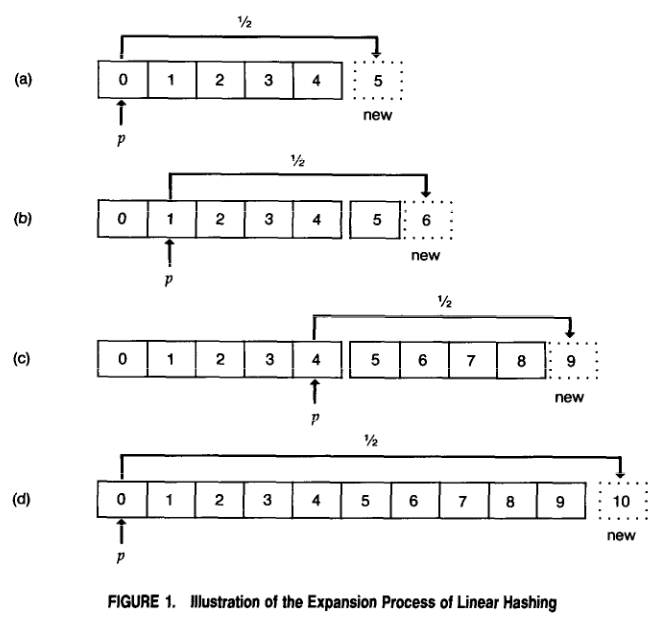
(传统哈希表拓展容量的办法,这点我们在之前已经做了阐述)
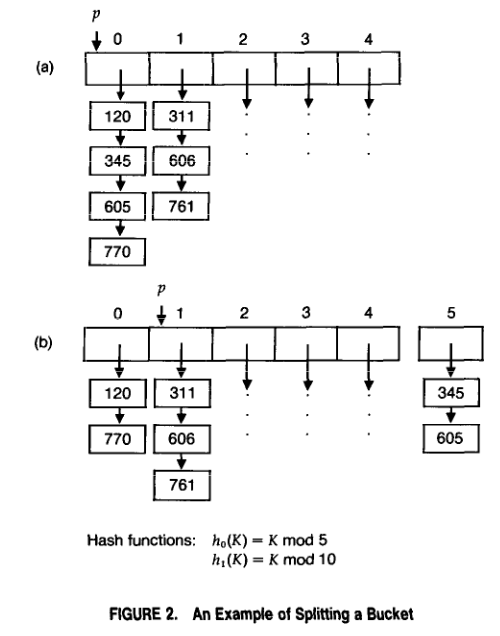
文章中设计的新拓展办法,实质是对传统方法的二次改进:
1. 增加一个名为“Bucket”(桶)的层,**“Bucket”之内同样是一张哈希表**
2. 改变数据存储计算流程,调整为“先计算存储于哪一个桶,再计算位于桶内的哪一个位置”
3. 这样当需要拓展容量的时候,我们只需要添加一个新的桶(因为一个桶的内部就是一张哈希表,所以实际上依旧是添加了许多数据项)
4. 再对“桶”一层的数据做重分布就可以解决容量拓展的问题了(这就像转移大量文件时,我们往往倾向于先分类打包为不同的压缩包以后,再做处理文件的转移工作一样)
5. 因为重分布涉及的对象数量变少,故成本也降低了不少
6. 层次的添加意味着计算流程也需要作出对应的调整,这可以通过引入新的哈希函数解决
PostgreSQL 的动态哈希表,便是对于这种思想的实现,同时结合了自己的应用场景,做出了进一步的改进。
实践分析:PostgreSQL 的动态哈希表需要额外应对怎样的问题?
所有的数据结构与模型,在具体实践的时候,都需要结合具体的场景展开实现,而在 PostgreSQL 中,动态哈希表须注意到:
1. 并发访问问题,数据库的数据访问往往牵涉到多个而不是一个用户(同时这个数量往往非常庞大)
2. 数据来源多元化问题,在原始版本的《Dynamic Hash Table》文章中,仅考虑到了数字这种最基本的数据,而在 PostgreSQL 的动态哈希表中,我们还需要考虑到 “字符串” 等数据的存储
3. 调试便利化问题,数据库是很复杂的软件,常常可能发生各种出乎意料的问题,需要一定方法帮助研究人员来获得更多信息,以便设计出更可靠的模块来
而 PostgreSQL 所设计的解决策略,可以用如下的内容来展开理解:
PostgreSQL 的分区哈希表与 FreeList:解决并发访问问题
并发访问问题,之所以引发困扰,就在于对于同一资源的无序争夺,将使得最终的运行结果依赖于访问资源的先后顺序(竞争条件)。
而想要解决这种困扰,我们就需要尽量地让对资源的应用操作由完全的无序,变为可控的无序,至少,要保证一个使用方在使用数据的时候,不会出现被其它使用方直接篡改的情况。
这就需要依托锁机制,即对资源的使用情况,做一个状态登记(如果锁变量被设置为占用状态,就需要暂缓对于资源的使用;而如果锁被释放,即被设置为非占用状态,即可以启动对于资源的使用),在 PostgreSQL 中,动态哈希表使用的是 SpinLock (自旋锁),实现位于 `src/include/storage/spin.h` 中。

有了解决的思路与对应的机制,接下来所需要思考的问题,就是在于如何存储这些机制所需要参考的决策信息,而 PostgreSQL 的解决方法,就设计了一种名为 FreeList 的数据结构,用于登记锁的使用情况(**以及哈希表的整体使用情况**),同时将使用了锁机制的哈希表,称呼为“分区哈希表”(A partitioned table)。

(FreeList 的定义,当 nentries 超过了 max_bucket,即哈希表容量到达极限以后,PostgreSQL 将会拓展哈希表的容量)


HASH_FUNCTION加一个桶,然后做重分布,**注意分区哈希表是无法拓展容量的**,因为并发访问下,锁的占用时间不可预测,而重分布会引发整张表的不可用,这就会引入系统出现重大问题的风险)

(FreeList 的操作宏,在没有启动分区模式的时候,所有的数据使用访问将会集中于 FreeList 数组的第一个元素,即 freelist[0],而在开启分区模式的时候,数据访问将会分散于 FreeList 数组的不同位置(IDX 的含义就是 FreeList 数组的对应下标,Index),因此降低了同时访问同一位置的可能性,这就是“分区”的内涵所在)
设立多个哈希处理函数:解决数据来源多元化问题
这一部分内容相对简单,单一化来源的数据(如原论文中的数字数据),我们只需要“兵来将挡”即可,而多元化来源的数据,那就加入对应的处理操作,“兵来将挡,水来土掩”,具体情况具体处理就行。

(PostgreSQL 允许用户定义自己的哈希函数,同时为字符串和原始二进制数据提供了对应的支持函数)
hash-statistics 宏指导下的数据收集机制:解决调试便利化问题
只需要我们在调试内核的时候,开启 HASH_STATISTICS 宏,PostgreSQL 就可以为我们收集哈希表数据的访问情况与哈希数据的碰撞情况。


(hash_stats 函数可以帮助输出统计出来的数字,在不开启 HASH_STATISTICS 宏的情况下,这些代码不会被编译出来)
实现分析:PostgreSQL 如何实现动态哈希表?
初期阅读的实现代码的时候,难免会被 `HASHSEGMENT`,`HASHBUCKET`,`HASHELEMENT` 三个数据类型的关系所困扰,但当我们有了对《Dynamic Hash Tables》这篇文章的理解之后,难题也随之解开。


(源代码的注释实际上描述的就是一个这样的结构)
而在这个基础上,只需要理解下面的两部分内容,就可以真正理解动态哈希表模块。
hash_search 函数:对于哈希表数据的查询、增加与删除
hash_search 函数依托 hash_search_with_hash_value 函数实现,集成了动态哈希表的全部重要操作,其流程如下所示(我选取了重点的部分加以分析,他们代表了源代码中最重要的部分):

可以发现,这实际上就是对于普通哈希表的数据存取操作的整合,并结合了 PostgreSQL 自身应用场景的特点进行了改造。
应用分析:动态哈希表助力缓存 PostgreSQL 的关系表数据
relation_open 函数在 PostgreSQL 中发挥着十分重要的支撑作用,而它本身依靠的 RelCache,即 PostgreSQL 关系数据缓存模块,实际上就是依托于动态哈希表加以实现。

我们在这里展现了 DefineRelation,relation_open,RelationIdGetRelation 函数之间的一部分代码,其中 DefineRelation 是 `CREATE TABLE` 等语句所对应的内核级实现的重要部分,而 relation_open 在 DefineRelation 中同样属于一个重要组成部分,它是一些配套操作与 RelationIdGetRelation 的整合(因此在源代码注释部分表示:relcache 承担了真正的工作内容)。

而当我们把目光放到 `RelationIdGetRelation` 的时候,可以发现它最重要的工作内容,就是调用了 `RelationIdCacheLookup` 以使用 oid 尝试查找到对应的关系型数据(如果没有找到,则会尝试创建一个)。
而当我们继续顺藤摸瓜查看 `RelationIdCacheLookup` 的定义的时候,可以发现它实际上是一个宏,宏的内容则就是对于动态哈希表模块的一则应用,由此可以发现动态哈希表对于 PostgreSQL 的影响之大。

![]()
写在最后
PostgreSQL 内核的动态哈希表模块可谓是内核中的重中之重,非常值得学习。