

简单讨论 PostgreSQL C语言拓展函数返回数据表的方式

文一
在 PostgreSQL 中,pg_get_functiondef 函数可以帮助我们构造用户自定义函数(User-Defined Function)创建时的语句,其实现原理流程如下:
1. 接收用户指定的 OID
2. 根据 OID,在系统表 pg_proc 中搜寻对应函数记录
3. 根据函数记录对应的各部分信息,重新组装 CREATE FUNCTION 查询语句
4. 反馈给用户对应的结果
对应代码参考如下:
/* 代码经过精简,提取自 src/backend/utils/adt/ruleutils.c*/Datumpg_get_functiondef_internal(PG_FUNCTION_ARGS){ /* 提取记录于系统缓存中的函数描述记录,根据 OID 获取指定的条目 */ proctup = SearchSysCache1(PROCOID, ObjectIdGetDatum(funcid)); proc = (Form_pg_proc) GETSTRUCT(proctup); /* 根据系统数据表 pg_proc 中的各个属性的记录,重新组装 CREATE FUNCTION 语句 */ /* 如:此处自记录中获取函数的名称 */ name = NameStr(proc->proname); /* 随后,它就成为了最后导出的 SQL 语句中的一部分 */ appendStringInfo(&buf, "CREATE OR REPLACE %s %s(", isfunction ? "FUNCTION" : "PROCEDURE", quote_qualified_identifier(nsp, name)); /* 其它部分的逻辑与之相通,区别在于对应 CREATE FUNCTION 语句的部分不一样 关于 pg_proc 各个条目的具体内涵,参考: https://www.postgresql.org/docs/devel/catalog-pg-proc.html */ // ... /* 最终,返回构造完成的 SQL 语句 */ PG_RETURN_TEXT_P(string_to_text(buf.data));}
可惜的事情在于,这个有用的函数一次只能够指定一个 OID,提取一个 UDF 函数的记录,因此在很多时候,它的应用是受到了一定的限制的,也因此,我计划对 pg_get_functiondef 做一个简单的加强工作,策略也非常简单,即组装一条查询语句,依托 PostgreSQL 的 SPI 接口,获取反馈结果,再将其呈现出来,原理图示如下:

最终的展现结果,我规划为呈现如下的形式:

这就需要我们对如下的两条知识,有一个基本的了解:
1. Set-Returning-Functions (SRF 函数),即返回多条数据记录而并非单条记录的拓展函数
2. PostgreSQL 文档《C-Language Functions》中 Returning Rows (Composite Types) 的有关部分
SRF 函数简介:以一个精简版本 generate_series 函数的实现为例
SRF 函数与一般的函数相比,其区别在于它们返回的是多条数据记录,而并非单条数据记录,如下面所示:
SELECT random(); /* 典型的非 SRF 函数,random 函数返回一条包含一个随机数字的记录 */SELECT generate_series(1, 3); /* 典型的 SRF 函数,generate_series 函数根据用户的输入构建数字序列,如此处的 [1, 2, 3] */
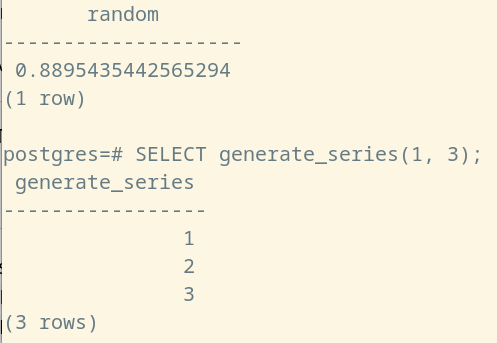
(这个简单的实验可以轻松地展现出两者的差别)
而想要实现 SRF 函数,我们就必须依托于它所提供的机制,其基本流程如下:

而联系 generate_series 的代码实现,我们可以更为深刻地了解它的工作方式:
/* 我们选择最具有 SRF 代表性的一个实现作为研究的案例 代码经过精简与改编,原始代码请参考 src/backend/utils/adt/int.c*//* 这里改编出了一个可以按照递增方式构建序列的 generate_series 函数 可构造出诸如 [1, 2, 3], [10, 11, 12, 13] 的序列 */typedef struct{ int32 current; /* 当前的数字 */ int32 finish; /* 数字序列的结束数字 */} generate_series_fctx;Datumgenerate_series_step_int4(PG_FUNCTION_ARGS){ FuncCallContext *funcctx; /* 函数调用上下文 */ generate_series_fctx *fctx; /* 存储自定义信息 */
/* 初始化工作 */ if (SRF_IS_FIRSTCALL()) { /* SRF 调用上下文初始化 */ funcctx = SRF_FIRSTCALL_INIT();
/* 为自定义内容分配内存 */ fctx = (generate_series_fctx *) palloc(sizeof(generate_series_fctx));
/* 在 fctx 中存储用户输入,即:数字序列的开始与结束数字 */ fctx->current = PG_GETARG_INT32(0); fctx->finish = PG_GETARG_INT32(1);
/* 保存自定义信息到上下文中 */ funcctx->user_fctx = fctx; }
/* 获取函数调用上下文用于得到自定义存储信息 */ funcctx = SRF_PERCALL_SETUP(); fctx = funcctx->user_fctx;
if (fctx->current <= fctx->finish) { fctx->current++; SRF_RETURN_NEXT(funcctx, Int32GetDatum(fctx->current)); /* 返回一条构造的数据记录 */ } else SRF_RETURN_DONE(funcctx); /* 结束全部工作 */}
PostgreSQL C语言拓展函数返回复合类型的方法
在展开详细论述之前,我们需要建立如下的两点认识:
1. PostgreSQL 所有的拓展函数都服从 “关系型数据进,关系型数据出” 的原理
因此所有在C语言拓展函数中反馈数据给用户的行为,本质上都是在构造关系型数据,区别在于一般的返回接口,如 **PG_RETURN_INT32**, 是将简单的数据传递给 PostgreSQL,让其帮助构造一条格式如 `CREATE TABLE example (value INTEGER);` 的数据,而想要返回复杂的数据,则需要我们自己手动构造元组(包括元组格式的构造工作与数据的填充工作)。
2. 关系型数据的构造过程可以理解为C语言二维数组的填充过程
因此,在 PostgreSQL 文档中提及的 heap_form_tuple 和 BuildTupleFromCStrings 两种构造元组的方式殊途同归,都是要求我们提供二维数组和元组描述符(TupleDesc)作为输入的数据,区别在于,heap_form_tuple 所要求的 Datum 数据(这是 PostgreSQL 中统筹各类数据的通用桥梁类型,就像C语言可以使用 void* 代指各类指针一样),还需要 PostgreSQL 做一轮转换才可以呈现为给用户使用的字符串数据,而 BuildTupleFromCStrings 所要求的字符串数据,则直接就会成为最终摆在用户面前的成果。
而在这两点认识之上,也就有了构造元组并且返回元组的完整流程,作图如下(PostgreSQL 格式灵活,方式多样,这里我们所描述的仅为其中一种实现方案,流程供参考):

而一个用于参考的函数,如下所示:
/* 这个示范函数的完整实现项目请参考: https://atomgit.com/wenyi/pg_return_composite_data.git*/Datum pg_return_composite_data(PG_FUNCTION_ARGS){ char *name; int age; int len; TupleDesc tuple_desc; AttInMetadata *tuple_meta; char **tuple_values; HeapTuple tuple; Datum result;
get_call_result_type(fcinfo, NULL, &tuple_desc); tuple_meta = TupleDescGetAttInMetadata(tuple_desc);
name = PG_GETARG_CSTRING(0); age = PG_GETARG_INT32(1);
/* TABLE (name CSTRING, age INTEGER) */ /* 最终的结果表有两个数据项,因此填写 2 */ tuple_values = palloc(2 * sizeof(char*));
/* 为第一个数据项分配内存,填充数据 */ len = strlen(name); tuple_values[0] = palloc0(sizeof(char) * (len + 1)); memcpy(tuple_values[0], name, len);
/* 第二个数据项 */ tuple_values[1] = palloc0(sizeof(char) * (16)); sprintf(tuple_values[1], "%d", age);
tuple = BuildTupleFromCStrings(tuple_meta, tuple_values); result = HeapTupleGetDatum(tuple);
PG_RETURN_DATUM(result);}
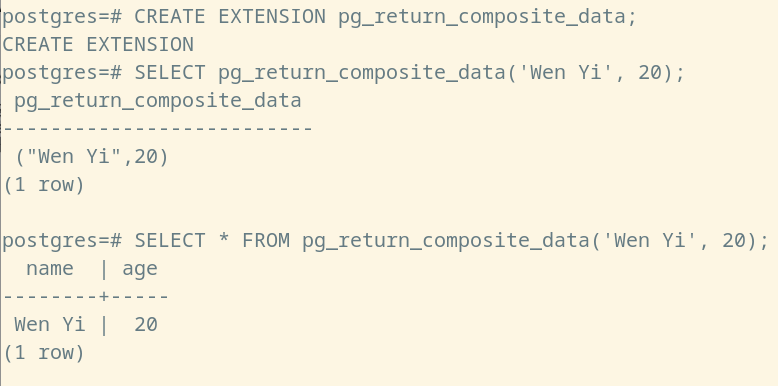
而该函数运行的结果,如下所示:
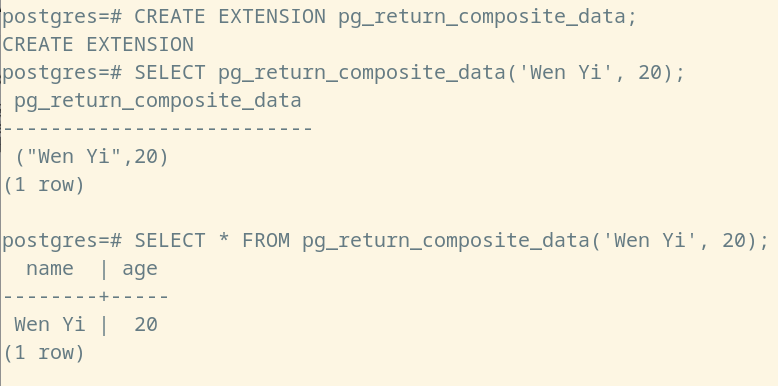
(注意:SELECT 将数据源放置位置的不同,将会影响最终的输出结果,这是因为他们分别对应不同的查询计划)
综合:返回数据表
现在,经过前面的讨论,我们已经对C语言拓展函数依托 SRF 机制返回多条数据记录和构建元组以返回复合记录有了基本的了解,而想要返回一张数据表,其实就是两者的整合,我们可以理解为将 SRF 机制中,将 SRF_RETURN_NEXT 函数中设置的返回内容,由简单数据类型构造而成的 Datum,转变为由构造后元组返回的 Datum,由此实现这项需求。
(增强后的 pg_get_functiondef 函数,可以输入多项 oid 了)
写在最后
我非常感谢 IvorySQL 社区选择我参与开源之夏的开发工作,也非常感谢 MOP 社区愿意提供这次发稿的机会。
开发内核途中遇到的最大问题,就在于发现国内的内核研究资料,依旧是过于残缺,这就需要更多有志于 PostgreSQL 的内核学习者们,尽力而为地补足这些细节性的材料,这样才可以实质性地繁荣中国的 PostgreSQL 生态。
不足还有许多,还请各位多多指教,谢谢!