

pg_resetwal 实现原理

文一
pg_resetwal 实现原理
所有成熟的思考,都来自于细微的探索,我们将继续展开一系列分析,帮助更多的人走进数据库内核的世界,建设一个繁荣的,重视技术与原理的中国数据库生态。
pg_resetwal 负责清理 PostgreSQL wal 日志文件,同时可以在需要的时候重建 pg_control 文件,而要想理解它所工作的原理,我们就必须对下面的知识,建立基本的了解:
简单理解 PostgreSQL wal 日志机制起到的作用
理解日志机制的作用,除了为数据库的管理人员提供重要的参考信息以外,最重要的集中于下面的两点:
- 故障恢复 在数据库出现故障的时候,将保存有数据读写操作的日志,结合已经存储于磁盘上面的数据,即可以实现快速故障恢复。
(一种对于日志机制流程的简化描述,用户的指令在交付执行时,会自动构造出对应的日志来,放置于缓冲区之中,并最终写入磁盘,因此,故障恢复时,只需要把那些尚未写入磁盘的内容,写入进去,即可以快速地恢复服务)
- 集群部署 通过把记载有数据读写操作的日志传输给其它的节点,就可以实现集群部署,进而集合 Raft 等算法,实现高可用,分散读写压力等。
而日志的本质,就是按照某种方式组织起来的数据文件,尽管其组织的要素往往仅有四个(在我阅读完成一定的数据库代码后,得出来的一个总结):
- 操作所对应的时间
- 操作所对应的指令
- 操作所对应的数据
- 操作完成的状态
但是因为实际工程实践中,因为各种数据库的设计思路,应用场景不甚相同,因此最终呈现出来的表现形式,在库内所承担的责任,乃至于对外所用术语等,往往会不一样,如在 MySQL 中,记录着数据操作的日志,被称为 “binlog”,在 PikiwiDB 中,则有“slowlog” 等。
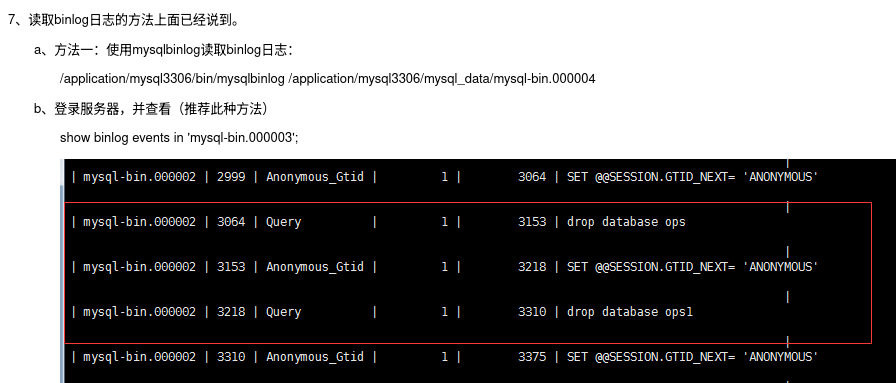
(图片截取于某篇介绍 MySQL binlog 的文章)
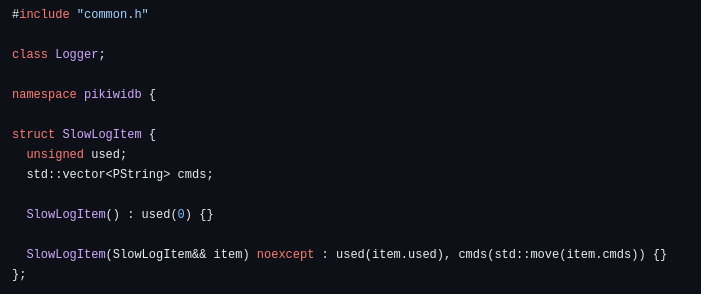
(图片截取于 PikiwiDB 的一部分源代码,可以看出,因为 PikiwiDB 是一款 Key-Value 数据库,所以其日志结构的设计,就简单一些)
在有了一个大体的了解之后,我们可以再对 PostgreSQL 中的 wal 归档,做一个了解,他们同样是我们理解 pg_resetwal 的重要支撑:
wal 归档
领域交叉融合的一个重要表现形式,就是我们可以用发生于另外一个领域的专业术语,解读发生于我们这个领域的某一项工作,在这里,我们摘取华为云在对象存储(OBS)中,对于归档存储的解析:
归档存储(OBS Archive)是OBS存储类别的一种,适用于很少访问(平均一年访问一次)数据的业务场景
而在 PostgreSQL 之中,wal 的归档,即代表日志文件中所记录的数据管理操作,以及所对应的数据,已经正式落地磁盘,因此即使对应的 wal 日志遭到了破坏,乃至于删除,也不再会影响到存储于磁盘上的数据。
对检查点(Checkpoint)做一个了解,则可以帮助我们更好地奠定理解 pg_resetwal 的基础:
检查点(Checkpoint)
在工程的实践当中,一种行之有效的办法,就是把工程当中的工作,分解为一个又一个的时间节点加以推进,如在 PostgreSQL 中,在内核补丁审核程序 Commitfest(可以把它理解为 Github 中的 Pr)中,即会规划一个审核的周期,进而同数个大版本的内核测试与发布,结合到一起来统筹推进;而在 PikiwiDB 中,社区的组织方式便是在每一周召开一次关于内核研发的周会,并将任务发布于社区的 weekly 周报之中,挂图作战进行推进。
(PostgreSQL CommitFest 程序截图)
(PikiwiDB 的 weekly 截图)
而在 PostgreSQL 中,检查点(Checkpoint)的内涵,引述文档中的内容,则如下所阐述(注意在 PostgreSQL 之中,即使是单独的查询语句,也是视作为一个事务而处理的):
检查点是一组分布于事务序列当中的点,在(每一个特点的)检查点之前,PostgreSQL 保证堆表数据与索引数据文件,及其所有的信息,已经被写入磁盘。
Checkpoints are points in the sequence of transactions at which it is guaranteed that the heap and index data files have been updated with all information written before that checkpoint.
而在 PostgreSQL 中,描述检查点的代码,罗列如下所示:
typedef struct CheckPoint
{
/* 下一个我们可以用来创建检查点的 wal 日志区域, redo start */
XLogRecPtr redo;
/* 当前的时间线 ID */
TimeLineID ThisTimeLineID;
/* 先前的时间线 ID
如果当前的记录开启了新的时间线,则记录之;
否则同当前时间线 ID 保持一致
*/
TimeLineID PrevTimeLineID;
/* 是否开启全页写入? */
bool fullPageWrites;
/* 当前日志的级别? */
int wal_level;
/* 下一个可用的事务 ID (Full 版本的 id 还会记录发生了多少次的事务号迭代) */
FullTransactionId nextXid;
/* 下一个可用的 OID */
Oid nextOid;
/* 下一个可用的事务 ID */
MultiXactId nextMulti;
/* 用于标识多个事务 ID,这点我们会在后续的文章中做详细论述 */
MultiXactOffset nextMultiOffset;
/* 数据库集簇级别的最老版本的尚未被清理过的事务 ID (需要联系冻结机制) */
TransactionId oldestXid;
/* 最老版本的尚未清理过的事务 ID 所在的数据库的 OID */
Oid oldestXidDB;
/* 集簇级别的尚未清理过的事务 ID,不过这个 ID 不带有“第几轮迭代的信息” */
MultiXactId oldestMulti;
/* 最老版本的事务 ID 所处的数据库 OID,事务 ID 同样是不带 “第几轮迭代” 的 */
Oid oldestMultiDB;
/* 检查点所对应的时间 */
pg_time_t time;
/* */
TransactionId oldestCommitTsXid; /* oldest Xid with valid commit
* timestamp */
TransactionId newestCommitTsXid; /* newest Xid with valid commit
* timestamp */
/*
* Oldest XID still running. This is only needed to initialize hot standby
* mode from an online checkpoint, so we only bother calculating this for
* online checkpoints and only when wal_level is replica. Otherwise it's
* set to InvalidTransactionId.
*/
TransactionId oldestActiveXid;
} CheckPoint;
也正是因此,我们完全可以将检查点,视作为故障恢复中的一个又一个“时间节点”,以此为基础,展开我们数据恢复的工作。
不过数据恢复等知识超出了本文所讨论的范围,因此在这里我们按下不提。
同时,我们也需要对于 PostgreSQL 数据库的“状态”,做一个对应的了解:
PostgreSQL DBState 简介
用于标识 PostgreSQL 服务端在最后一次退出时的工作状态,于 PostgreSQL 启动的时候被调用,用以了解 PostgreSQL 是否需要展开恢复工作等,具体的情况如下所示:
/* DBState 代表 */
typedef enum DBState
{
/*
字面意义上面看,是代表服务端启动时,
但在实际中,它更多是象征意义,无实际用处
*/
DB_STARTUP = 0,
/* 代表 PostgreSQL 正常退出,无需额外措施 */
DB_SHUTDOWNED,
/* 代表 PostgreSQL 在恢复过程完成以后顺利退出 */
DB_SHUTDOWNED_IN_RECOVERY,
/* 代表 PostgreSQL 正在关闭过程中 */
DB_SHUTDOWNING,
/*
代表 PostgreSQL 在恢复过程中出现故障退出,可能会存在一定的数据丢失
*/
DB_IN_CRASH_RECOVERY,
/*
代表 PostgreSQL 在归档途中出现故障退出,这可能是因为数据文件损毁,使得最终能够恢复到的状态,是一个早于目标节点的节点
*/
DB_IN_ARCHIVE_RECOVERY,
/*
代表 PostgreSQL 在运行途中被意外地中断运行 */
DB_IN_PRODUCTION,
} DBState;
而理解 DB_IN_CRASH_RECOVERY 与 DB_IN_ARCHIVE_RECOVERY 的区别,就在于我们需要对 Point-in-Time Recovery, PITR(基于时间点的恢复)做一个了解,PITR 的思路便是对我们前面图片说明 wal 日志机制的一个概念性概括,便是在一个基础数据库版本结合日志的机制上,使得数据库的状态可以根据日志的记录等,推行到某个特定的版本上面去(只需要存在日志,就可以实现迭代,较新版本与较旧版本都可以),而归档的概念,先前我们也都有所介绍,便是已经落地到磁盘上面的 wal 日志,归档恢复时所产生的错误(DB_IN_ARCHIVE_RECOVERY),便是在这种日志上面产生的,而DB_IN_CRASH_RECOVERY,更多是对于那些尚未落地到磁盘的日志而说的。
在建立了对 wal 归档机制与检查点等机制的基础理解之后,对 pg_control 文件做一个基本的了解,便是我们需要掌握的最后一个理解 pg_resetwal 的基本原理,参考下面的论述:
pg_control 文件的基本介绍
在 pgPedia.info 网站上面,作者用一句话描述了 pg_control 文件存在的意义:
A file containing information about the server's internal state.
一个包含着 PostgreSQL 服务端内部运行状态信息的文件。
而在 src/include/catalog/pg_control.h 中,PostgreSQL 在源文件中定义了 pg_control.h 的组织形式(特别提醒:尽管放置于 catalog 目录中,但是 pg_control.h 中并不是一张系统数据表,而是一个按照特定格式组织的二进制数据文件)
这里,我们可以查看 ControlFileData (这便是描述 pg_control 的结构体)的代码,如下所示:
typedef struct ControlFileData
{
/* 用于唯一标识服务端, 具体代码参考 BootStrapXLOG 函数 */
uint64 system_identifier;
/*
用于标识 pg_control 文件版本, 等价于 PostgreSQL 主版本
如 PostgreSQL 17 -> 1700
*/
uint32 pg_control_version;
/*
用于标识系统目录的版本,采用 YYYYMMDDN(年月日)形式,
N 代表该文件被改动的次数
具体参考 catversion.h
*/
uint32 catalog_version_no; /* see catversion.h */
/*
标识系统的状态,参考上面的论述
*/
DBState state;
/* pg_control 最后被更新的时间 */
pg_time_t time;
/* 最后一个检查点所对应的 wal 日志区域 */
XLogRecPtr checkPoint;
/* 用于描述最后一个检查点 */
CheckPoint checkPointCopy;
/* 当前的尚未归档的日志号 */
XLogRecPtr unloggedLSN;
/* 下面的数据是 PostgreSQL 在正式启动前,必须将数据状态所达到的临界时间点 */
/*
在日志归档恢复期间,当我们将 wal 日志刷入磁盘时,它会被更新为最新版本
的重放 LSN
不展开归档恢复时,其为 NULL
*/
XLogRecPtr minRecoveryPoint;
TimeLineID minRecoveryPointTLI;
/*
当备份工作结束时,其会被设置为 NULL;
否则设置为备份工作终结前的最小恢复点
*/
XLogRecPtr backupStartPoint;
XLogRecPtr backupEndPoint;
/* 是否需要自备份中恢复? */
bool backupEndRequired;
/*
决定日志是否可以被用于归档或者 hot standby 的一组参数
*/
int wal_level;
bool wal_log_hints;
int MaxConnections;
int max_worker_processes;
int max_wal_senders;
int max_prepared_xacts;
int max_locks_per_xact;
bool track_commit_timestamp;
/* 元组的对齐要求 */
uint32 maxAlign;
/* 常量 1234567.0,这是为了测试硬件的浮点兼容性 */
double floatFormat;
#define FLOATFORMAT_VALUE 1234567.0
/* 用于确认本数据库配置同后端服务器可执行文件兼容 */
/* 数据库的块尺寸 */
uint32 blcksz;
/* 对于庞大的关系型数据而言,一个段对应多少数据块? */
uint32 relseg_size;
/* wal 日志中的块尺寸? */
uint32 xlog_blcksz;
/* wal 日志中的段尺寸? */
uint32 xlog_seg_size;
/* 目录名称所对应的域的尺寸 */
uint32 nameDataLen;
/* 在一个索引当中的列的最大数目 */
uint32 indexMaxKeys;
/* TOAST 数据表中,chunk(桶)的尺寸 */
uint32 toast_max_chunk_size;
/* pg_largeobject 中,chunk(桶)的尺寸 */
uint32 loblksize;
/* float8, int8 等类型是否为按值传递? */
bool float8ByVal;
/* 数据是否处于 checksums 保护之下? 没有则写为 0 否则写版本号*/
uint32 data_checksum_version;
/* 随机的字符串,用于验证数据库集簇的唯一性 */
char mock_authentication_nonce[MOCK_AUTH_NONCE_LEN];
/* 上述所有内容的 crc 校验码,必须写在最后 */
pg_crc32c crc;
} ControlFileData;
而对于 pg_control 文件的读写,本质上就是把这个结构体的内容,以二进制的方式,反复写入与读取。所以我们只需要了解代码,和前面阐述的机制,即可以了解其重点之所在。
实现流程分析
接下来,让我们来查看 pg_resetwal 工具的实现,参考下面的部分:
首先第一部分,定义了 pg_resetwal 所接收的参数,以及其基本的处理办法,这种我们可以通过阅读 getopt_long 的文档加以解决(它超出了本文的讨论范围,所以我们不会展开,我们只需要知道,这里做的就是对接收什么参数,参数对应什么字母,含义是什么作了说明)。

而后的这部分代码,便是初始化基本的日志环境,环境变量等,值得一提的在于 PG_COLORS 这个环境变量,它用于处理 PostgreSQL 日志输出时候的高亮,参考文档如下:

(采用键值对方式进行,而输出的色彩代码,则是有一定的历史渊源)

(可以参考 vt-100 的图形图像色彩代码的描述,我们的 terminal,正是对于过去这种老式图形设备的一种模拟)
之后便是对于传入参数的分类处理,首先参考基本的部分:
(第一部分,打印帮助信息和版本信息)
(第二部分,根据传入数据,分别设定参数:如果用户指定了某个参数,则调整内部对应参数至用户设定参数,否则即使用默认参数)
之后的代码,则是一些判断 PostgreSQL 服务端是否正在运行(策略:检测 postmaster.pid),读取 pg_control 文件(同时检测其内容有效性,在无效时 pg_resetwal 会根据默认值计算数据)的代码,因为其过程繁琐,同时原理简单,我们不做过多分析。
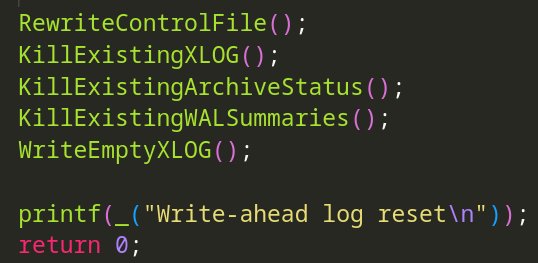
(最终便是在用户允许的情况下,重建控制文件,删除既有 wal 日志,清理归档标志文件(用于标记 wal 归档是否完成?),以及 WAL summary files(wal 概括文件))
有关 WAL summary files 的用义,参考下面的论述:
WAL summary files 简介
一个 wal 概括文件由 tablespace oid, relation oid 和 relation fork(relation fork 是 PostgreSQL 对于关系型数据的一种存储策略,可以用 git 仓库中主线和支线的关系辅助理解) 进行索引。对于每一个 relation fork 而言,它存储着 wal 日志将会修订的数据块。
同时,wal 概括文件同样存储着 “受限的数据块”, 当 relation fork 被创建出来或者在相关的 wal 范围内受到截断的时候,它会被设置为 0, 同时在其他的情况之下,它将会被设置为 relation fork 被截断前的最短长度。
PostgreSQL 17 中引入了 pg_walsummary 工具帮助我们阅读 wal 概括文件,上述内容摘录自 pg_walsummary 文档,感兴趣的读者欢迎阅读相关内容。
写在最后
所以,pg_resetwal 本身的复杂性,并非其原理的复杂(因为根据默认值和用户输入组合调整数据,是很多业界人员都理解的一种编程思路),而在于它糅合了很多外延的相关的概念。
理解 pg_resetwal 工具可以很好地促进我们理解 PostgreSQL wal 的日志机制,期待其为读者们带来有益的思考,在这里感谢 IvorySQL 社区的任娇老师,牛世继老师给予我参与内核研发的机遇,感谢 PikiwiDB 社区的于雨老师,给予我跨界思考数据库的机会(Key-Value 数据库中很多的理念便是对于传统关系型数据库的简化,而他们因为相对简单,产生出来的很多经验又可以促进关系型数据库的发展),也要感谢 MOP 社区的吴洋老师,谢谢各位给予的种种指导。