

IvorySQL 贡献经历谈:如何参与内核研发?

文一
开源之夏是非常有意义的事情,它提供了一个平台以供我们参与到很多前沿的项目中去,本文将就如何参与到 IvorySQL 的内核研发中展开讨论,祝愿更多的人参与到 PostgreSQL 相关的数据库开发中,建立对于后端软件开发/数据库开发的一个了解。
什么是数据库内核研发?
建立对于数据库内核研发工作的基本理解,是我们参与类 PostgreSQL 数据库内核研发的基础,在这里,我们首先需要回顾后端开发的基本概念,参考下面的内容:
建立对后端开发的基本理解
后端开发可以理解为设计一种可以实现双向数据传输的软件,其中,被称为“服务端”的软件部分,负责在本地接受来自于外部用户/主机的连接,并根据某种设计好的协议,以及用户的某种指示(配置文件乃至于数据往往存储于某个本地的文件夹上面),实现与外部数据传输,如图所示:

而在 PostgreSQL 中,postgres 即为服务端软件的代称,它依据放置于 “PGDATA” 目录中(专门用于存储配置文件及其数据的文件夹)的内容展开工作,如图:

(-D 指示了 PostgreSQL 存储数据与存放目录的地址,而如何初始化这个目录呢?请使用 initdb 工具,方法是 initdb [你希望设定的 PGDATA 地址])
所依据的通信协议,可以参考 https://www.postgresql.org/docs/current/protocol.html 部分的文档(介绍 PostgreSQL 的数据包是如何组织的)。
而被称为“客户端”的软件部分,负责主动连接服务端,按照用户要求发送指令给服务端加以处理。

这种指令具体是什么,取决于服务端软件与客户端软件的设计乃至于其所处的领域,如在 Redis 中,倘若我们希望读写数据,只需要按照 Redis 对于键值对的管理方式,即可以解决问题,如图:

而到了 PostgreSQL 之中,我们所需要做的事情,便在于按照 SQL 语言的模式,来处理问题,如图所示:

(psql 便是 PostgreSQL 中的客户端,其使用 SQL 以及一些内建指令,展开同服务端的工作)
而后端开发,乃至于数据库内核的开发,实际上便是在服务端与客户端上面下功夫,针对某种类型的任务,展开某种改进。
在后端开发的基础上,建立对于数据库内核开发的理解
我们可以把数据库内核开发工作视作为一种定向的后端开发工作(后端开发还包含着游戏服务器设计,音视频服务器设计等),这是因为,它往往便是针对某一种类型数据的管理而展开设计的。
而在 PostgreSQL 中,我们关注的便是关系型数据(关系型数据便是一种以二维表格形式组织起来的数据),一切的工作,则围绕对于关系型数据的管理而展开,简单来说,具体的工作可以划分为如下的类别(这里,我们以 https://commitfest.postgresql.org/ 上面的分类作为阐述的依据):
我们可以把 Patch 理解为开源工作中常常听到的 Pr,代表对于某种功能的改进与完善
- 对于 PostgreSQL 内核工程中某种 Bug 的修复 这往往来自于各地用户通过 bug 邮件列表的反馈意见,牵涉到某种不正常的工作行为等,这些 Patch 便是对于这些不正常工作行为的修订
- 对于 PostgreSQL 客户端的某种改进 这种情况往往是为 PostgreSQL 增加某种客户端工具,或者是对既有的某种客户端工具的细节改进,如 PostgreSQL 17 引入的 pg_walsummary 便是打印了 PostgreSQL wal 目录中的 summary 部分信息,用以展现 wal 文件的概括情况(即修订了哪一些数据块等)
- 文档的完善与更新 文档可以帮助我们更好的理解软件的原理和使用,PostgreSQL 的文档在指导用户使用 PostgreSQL 的同时,往往还帮助用户去定制 PostgreSQL 以适应自身的场景。
- PostgreSQL 运维信息的管理 数据库的维护需要诸多指标作为参考的依据。
- 性能优化与改进
- 过程性语言 过程性语言即是向 PostgreSQL 引入外部拓展,以支持使用某种编程语言以处理关系型数据。
- 对某种模块的重构 重构即是在实现对原有模块兼容性的情况下,重新设计并编写某种模块,以便提升灵活性,或者是性能,或者是可读性。
- 流复制 流复制是 PostgreSQL 提供的多机集群方案,可以实现 PostgreSQL 自单节点向多节点的拓展部署。
- 安全性 如对于密码安全性的增强等。
- 服务端的改进 对于某种工作行为的改进
- SQL 指令 引入新的指令以兼容最新的 SQL 标准,或是拓展某种语法。
- 系统管理 与运维工作息息相关,即指导 PostgreSQL 的某种全局性行为。
- 测试工作 测试便是模拟某种环境下 PostgreSQL 的表现,形式也非常简单,便是预先构造一组输入,并且设计好预期的输出,倘若执行测试的输出与预期输出不相符合,则证明存在某种问题。
- 其它
在大致树立了总体的概念之后,我们便可以开始开始对 PostgreSQL 的工程布局做一个了解,这是我们开发内核的基础(我将以一个简单的 Patch 以及我对于 IvorySQL 的开发经历,阐述如何实际参与内核研发,真实难度其实是远远低于我们的想象的,哈哈哈哈)
简单的改进也是对内核研发的参与:以 Patch 'int4->bool test coverage' 为例
在 PostgreSQL 的 Commitfest 程序中罗列着许多的 Patch,他们都代表着一种对于内核某个模块的改进思路,理解这些 Patch 往往就意味着我们熟悉了 PostgreSQL 的某一种模块,乃至于某种对于软件的改进思路(所以如果你成功地熟悉了足够多的 Patch,你也就成为了一名优秀的 PostgreSQL 内核研发者,须知即使是到 PostgreSQL 17,总体的 Patch 都没有超过6万个,别被这个数字吓到,许多模块对应着十个乃至于数以百计的 Patch,因此当你熟悉了对应模块以后,你实际的 Patch 阅读量会比你统计的 Patch 阅读量高上许多,哈哈哈哈)
好的,言归正传,让我们开始阅读这个 Patch 有关的背景信息,乃至于作者所期待的改进。
PostgreSQL 的测试体系简介(回归测试简介)
软件的测试对于软件的工作正确性而言是非常重要的事情,而在 PostgreSQL 当中,测试工作可以简化为如下的流程:

而对应到代码之中,则更是简单,参考下图:

(在 PostgreSQL 源代码文件夹中,通过 make check 执行测试操作)

(PostgreSQL 将会按照类别展开分组测试,测试需要涉及到内核工程中的各个重要模块,这样才可以最大避免地规避生产故障,ok 代表测试通过)

(测试有关的源代码位于 src/test 目录之下,里面牵涉到的文件很多,但是核心的原理就是执行某些 SQL 代码,验证其预期的输出)
更为详细的内容,可以参考文档中 https://www.postgresql.org/docs/current/regress.html (回归测试)的部分
有了了解之后,开始分析 Patch
而我们将要分析的 Patch,则与作者的一则发现有关系:
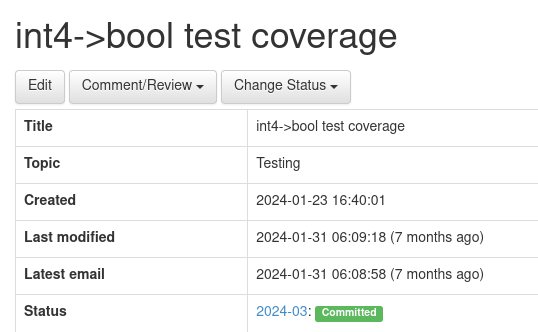
(Patch 在 Commitfest 页面上的主页信息,请参考 https://commitfest.postgresql.org/47/4789/)
作者邮件原文及其翻译
I was surprised to learn that 2 is a valid boolean (thanks Berge):
我非常惊讶地发现 2 (数字,译者注)也是一个有效的布尔值(感谢 Berge)
# select 2::boolean;
bool
──────
t
... while '2' is not:
... 同时我发现 '2' (字符串,译者注)不是有效的布尔值:
# select '2'::boolean;
ERROR: 22P02: invalid input syntax for type boolean: "2"
LINE 1: select '2'::boolean;
^
LOCATION: boolin, bool.c:151
The first cast is the int4_bool function, but it isn't covered by the regression tests at all. The attached patch adds tests.
第一则转换应用到了 int4_bool 函数,但这这个函数并没有被回归测试所覆盖到。因此我所提交的 Patch 补充了相关的测试。
Christoph
而作者的 Patch 内容也非常简单,我们提取关键部分信息如下:
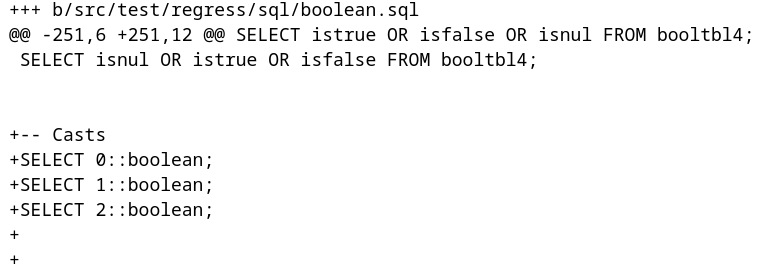
(增加了三条需要执行的 SQL 测试语句)

(以及三条语句所对应的期待输出)
而我们可以尝试执行其中的一条 SQL,可以发现这是一个简单的,但是长期以来被忽略的细节情况:

而社区在接收到这则细节性改进的 Patch 之后,很快地给予了批复:

(在2024年3月,该 Patch 合入 PostgreSQL 内核)
小结:内核研发实际上并不难
只需要我们保持着对于细节的注意力,小而稳健地推进,即可以慢慢成长为一名一流的 PostgreSQL 内核研发者。
而其它的诸多类 PostgreSQL,是针对某些特定的场景,对 PostgreSQL 做出的定向改进,我们不要将其看得那么难,而要将他们看成一件容易的事情(复杂的事情实际上是简单工作的不断组合)。
继续细化:如何参与 IvorySQL 贡献?
现在,我们已经理解了 PostgreSQL 内核研发是什么,以及如何研发 PostgreSQL 之后,理解参与针对某种场景定向优化的 PostgreSQL,也就不再算是一件非常困难的事情,继续参考下面的论述:

(IvorySQL 是一款为增强 PostgreSQL Oracle 兼容性而二次开发的 PostgreSQL 数据库,在代码上始终跟踪着最新版本 PostgreSQL)

(而 IvorySQL 则托管于 Github 之上,因此希望参与贡献的话,提交 Issue 与 Pr 即可)

(而在中国科学院与华为联合举办的 “开源之夏 2024” 中,我有幸成为中选的学生受邀参与到项目的开发之中,在这里非常感谢浪潮的任娇老师与牛世继老师)
而我所承担的项目职责,主要在于:
- 为 IvorySQL 增加新的 xml 函数
- 增强既有的 pg_get_functiondef 函数,增强其导出函数的能力
- 为他们编写对应的测试用例
而因为前面两篇所牵涉的具体原理已经在 [青年数据库学习会] 公众号上面发布,因此我并不会过多的讨论其细节,我们只需要了解的是,想要开发某种新的功能,或者是改进某种既有的功能,我们只需要了解其对应的模块的设计,原理以及对外接口,再融合我们自身的想法,即可以达成我们的目的。
以 xml 功能的增强为例,在我尝试向其加入 xmlisvalid 函数的时候,首先注意到的事情是:
- 既有的 xml 兼容函数都被设计于 ivorysql_ora 文件夹之中,而存放的地址,则位于 src/xml_functions 文件夹之下

换而言之,如果我需要加入新的 xml 兼容函数,就需要先从这里下功夫
- 因为 ivorysql_ora 是以拓展的形式涵盖于 PostgreSQL 整体的工程之中的,因此,我需要对 PostgreSQL
CREATE EXTENSION乃至于注册函数的CREATE FUNCTION有一个基本的了解

(PostgreSQL 文档中有关 CREATE EXTENSION 的部分信息)
- 之后,为了了解其实现目标,我需要查看 Oralce 对应的部分信息

- 根据 libxml 库的既有函数,实现功能

(最后实现的关键代码其实非常少,但是它的难点就在于需要很多铺垫的知识)
- 编写测试用例
在这里一定一定要注重沟通,现在我所犯下的一个巨大错误就是闷头开发,不注重同导师交流,最后忽略了很多项目中的细节信息,导致即使在开源之夏申报成功后两周内就完成了功能开发,也没能将产出立刻合入到代码库之中。

(两次遭到拒绝的 Pr 合入,因为我没能注重和导师沟通)
就以测试用例为案例,因为 IvorySQL 为了保持同 PostgreSQL 的兼容性,因此它设计了一个独立的为 Oracle 准备的 Oracle 兼容模式,而对应的测试也增添了 make oracle-check 选项,而我因为没有和导师沟通,忽略了这个事情,进而引入了很多不必要的沟通成本与误会,延缓了合入的效率,这点一定要引以为戒,不要单打独斗,一定要多和队友,导师,同行的朋友,以及跨领域的人多做交流,不然定然栽跟头。
言归正传,编写测试用例实际上和之前的 Patch 中的思路类似,就是引入一些范例的测试代码,同时给出输出的结果,然后放置于对应的测试用文件夹即可(这里又提到一个小细节,可以提供多个示范输出文件,这样只需要有一个符合,就可以通过测试,这非常适合于存在多种可能的正常输出的场景(IvorySQL 在 Oralce 模式与 PostgreSQL 模式下,同样的函数可能给出不一样的输出结果))
最终在于社区导师协调沟通以后,我的 Pr 顺利合入,由此也完成了 IvorySQL 的开源之夏工作任务,在这途中学习到了很多,尤其是严谨的软件开发精神。
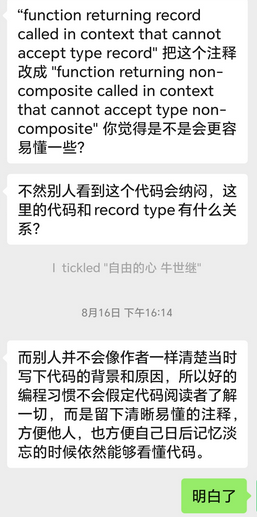
(对注释的把控都是很严格的,这有助于让我们编写出非常好的代码来,所以为什么要参与这种业界的前沿开源项目,正是因为在这途中可以学习到很多普通项目学习不到的东西)
写在最后
我们的“内核一周一审”栏目将会在每一周对某一个 PostgreSQL 的 Patch 展开解读,深刻挖掘其背后的原理,乃至于组织的思路,改进的思路等,期待这为各位投身于数据库内核开发带来更多有意义的借鉴与参考。
功夫全在于细节之处,而报团打堆才可以帮助我们更快的前进,期待更多的人投身于数据库领域之中,谢谢各位的支持。