

Redis 日志机制简介(一):SlowLog

文一
在 Redis 中,日志承担的作用多种多样,而我们所触及到的,统共分为四种,如下所示:
- SlowLog --- 用于记录 Redis 中查询较慢的指令
- HyperLogLog --- 用于服务 Reids 的数字估计算法
- Append-only Files, AOF --- 记录着所有被传递给 Redis 的写入操作指令,依托 AOF 日志,我们可以构建出完整的原始数据集(这就像流水账)
- Redis-Database, RDB --- 用于维护特定时间点的数据集合,可以用于点到点的数据恢复(这就像时间节点一样)
而限制于篇幅,我们仅仅向各位谈论 SlowLog, AOF 与 RDB 三类文件,而 HyperLogLog,更多地请读者根据自己的需要,自行做查阅。
SlowLog 简介
SlowLog, 慢日志,正如其名,负责记录那些执行时间超出某个期限的 Redis 指令(Slowlog implements a system that is able to remember the latest N queries that took more than M microseconds to execute),因为对于这些较慢指令的关注,往往是一个线上进行时的过程,因此,Redis 并不会把 SlowLog 真正写入文件,与之相对,它期待用户使用 SLOWLOG 指令加以查看(因此,SlowLog 是存储于内存之中的)。
SlowLog 的组织结构
所有的数据,只有被有效地组织起来才有用,Redis SlowLog 也不例外,它被组织为如下的结构:
/* Redis SlowLog 可以被视作为由这个结构组织而成的列表 */
typedef struct slowlogEntry {
/*
argv, argc 用于代指 Redis 用户输入的指令
如 SET a b 中,argc 就会被设置为 3,而 argv 则会逐个被设置为
SET a b (当然,实际情况会复杂一些,因为 argv 会被转化为 Redis 对象,用以便利数据的处理)
*/
robj **argv; /* 负责存储 Redis 的数据对象 */
int argc; /* Redis 指令参数的个数 */
long long id; /* 标识日志 ID */
long long duration; /* Redis 指令消耗的时间,用微秒标识 */
time_t time; /* 该 Redis 执行时的 Unix 时间值. */
sds cname; /* 客户端的名称 */
sds peerid; /* 客户端的网络地址 */
} slowlogEntry;
SlowLog 的实现原理:本质是对链表的二次组织
在这里,我们首先需要对 Redis argc, argv 中这个概念作出一定的了解,否则我们很难了解到 Redis SlowLog 在哪里存储了指令与数据,参考下图:
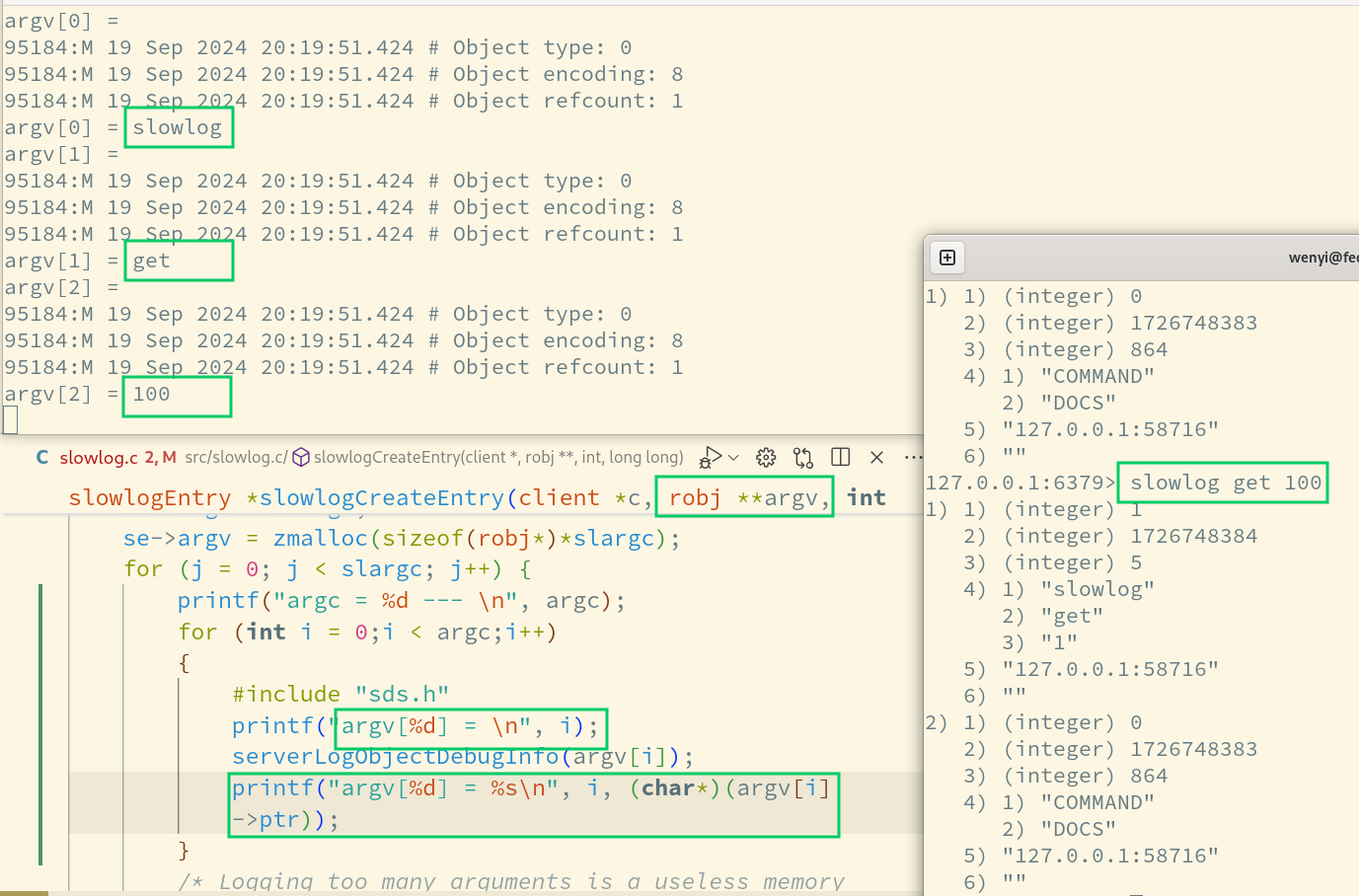
(在这里,我们对 Redis 进行了一定的修改,得出了这样的结果,如图所示,相信这样就可以帮助你看出 Redis 函数内 argc, argv 的含义)
同时我们应当对下面的一些知识点建立相应的理解(限制于文章的篇幅,我们期待读者自己探究清楚这些问题):
- Redis SDS 字符串的实现与对外接口(请参考 sds.c)
- Redis Object 有关信息的提取(请参考 debug.c)
弄明白这几个问题以后,让我们再回顾到 SlowLog 的实现之上,继续参考代码:
/* 创建 SlowLog 对象 */
slowlogEntry *slowlogCreateEntry(client *c, robj **argv, int argc, long long duration) {
slowlogEntry *se = zmalloc(sizeof(*se));
int j, slargc = argc;
if (slargc > SLOWLOG_ENTRY_MAX_ARGC) slargc = SLOWLOG_ENTRY_MAX_ARGC;
se->argc = slargc;
se->argv = zmalloc(sizeof(robj*)*slargc);
/* 把用户给出的 Redis 指令逐条记录下来, 可以当作为拼接字符串 */
for (j = 0; j < slargc; j++) {
/* Logging too many arguments is a useless memory waste, so we stop
* at SLOWLOG_ENTRY_MAX_ARGC, but use the last argument to specify
* how many remaining arguments there were in the original command. */
if (slargc != argc && j == slargc-1) {
se->argv[j] = createObject(OBJ_STRING,
sdscatprintf(sdsempty(),"... (%d more arguments)",
argc-slargc+1));
} else {
/* Trim too long strings as well... */
if (argv[j]->type == OBJ_STRING &&
sdsEncodedObject(argv[j]) &&
sdslen(argv[j]->ptr) > SLOWLOG_ENTRY_MAX_STRING)
{
sds s = sdsnewlen(argv[j]->ptr, SLOWLOG_ENTRY_MAX_STRING);
s = sdscatprintf(s,"... (%lu more bytes)",
(unsigned long)
sdslen(argv[j]->ptr) - SLOWLOG_ENTRY_MAX_STRING);
se->argv[j] = createObject(OBJ_STRING,s);
} else if (argv[j]->refcount == OBJ_SHARED_REFCOUNT) {
se->argv[j] = argv[j];
} else {
/* Here we need to duplicate the string objects composing the
* argument vector of the command, because those may otherwise
* end shared with string objects stored into keys. Having
* shared objects between any part of Redis, and the data
* structure holding the data, is a problem: FLUSHALL ASYNC
* may release the shared string object and create a race. */
se->argv[j] = dupStringObject(argv[j]);
}
}
}
/* 有关信息参考如上 */
se->time = time(NULL);
se->duration = duration;
se->id = server.slowlog_entry_id++;
se->peerid = sdsnew(getClientPeerId(c));
se->cname = c->name ? sdsnew(c->name->ptr) : sdsempty();
return se;
}
而随后一个重要的 API, slowlogPushEntryIfNeeded,实际上就是依托 Redis 链表接口的 API,将日志条目加入到整体记录当中,并在超限的时候,删除掉链表末尾的日志。
void slowlogPushEntryIfNeeded(client *c, robj **argv, int argc, long long duration) {
/* 是否开启 SlowLog 功能? */
if (server.slowlog_log_slower_than < 0 || server.slowlog_max_len == 0) return; /* Slowlog disabled */
/* 如果指令执行时间超过配置文件中设定的内容,则加入记录 */
if (duration >= server.slowlog_log_slower_than)
listAddNodeHead(server.slowlog,
slowlogCreateEntry(c,argv,argc,duration));
/* Remove old entries if needed. */
while (listLength(server.slowlog) > server.slowlog_max_len)
listDelNode(server.slowlog,listLast(server.slowlog));
}

(List 实际上就是一种用链表形式组织资源的办法,因为使用了 void* 统一指代资源,所以实际内容并不是非常重要)
而具体的指令实现,归根结底,就是对链表的内容做遍历然后输出,只不过需要联系到 Redis 的输出格式(以便于美观而易于阅读),参考如下:

对 SlowLog 的小结
这样,我们从关键点出发,就对 Redis 的 SlowLog 建立了一个坚实的了解,其它的 API 从本质上看便是在这些基础上面的延伸,实际上并不是非常地困难。
只要我们抓住了牛鼻子,什么事情也就都好办了。
写在最后
感谢给予我帮助的所有前辈,无论是袁国铭老师,张凯老师,悠然老师,于雨老师,牛世继老师,任娇老师,魏波老师,王其达老师,黄宏亮老师,吴洋老师,周正中老师,国武扬老师,都在不同程度与方面上促进了我们的进步,我们必将继续前进,与各个方面加强合作,继续建设一个更加繁荣的数据库内核生态。