

简单讨论 Linux 空设备的原理实现

文一
# 简单讨论 Linux 空设备的原理实现(Go 语言基础学习)
在阅读《分布式存储系统 --- 核心技术、系统实现与 Go 项目实战》的过程中,书内的一段论述激发起了我的好奇心,摘录如下:
---
(Linux 系统)文件的 I/O 接口实际上是 Linux 内核向用户态程序提供的交互接口。例如:
若要查看系统支持的所有文件系统类型,可以执行:cat /proc/file-systems
若要清理系统支持的 Page Cache,可以执行:echo 1 > /proc/sys/vm/drop_caches
尽管这些才做不操作表面上看似读写了存储数据的文件,但实际上,/proc/filesystems 与 /proc/sys/vm/drop_caches 并非真正的数据文件,内核并没有把数据存储在这些文件中。他们仅仅是用户态程序访问内核的接口地址。当这些文件被读取与写入的时候,内核的 proc 文件系统根据请求的路径执行相应的处理。本质上等同于调用内核 proc 文件系统的特定函数而已。
...
---
因为我在之前的 Linux 学习之中,对这些事情的背后原理,不仅仅是一无所知,甚至是连这些介绍性的文字,尚且是第一次阅读得到,所以这就激发起我,希望将通过一些内核方面的代码,把上述文字,彻底捉摸明白,而我所挑选的研究对象,便是 `/dev/null`(特殊的空设备,写入会立刻返回 EOF) 与 `/dev/zero`(特殊的空文件,读取会持续输出 '\0'),两个文件都归属于字符型设备,即以字节为单位展开读写工作并支持随机读写的设备。
好的,感谢 Kimi,它对于我找出 `/dev/null` 与 `/dev/zero` 的具体实现代码所在地给予了非常有用的帮助,现在,让我们打开 Linux 年内核源代码仓库,找到 `mem.c`,清从参考如图:
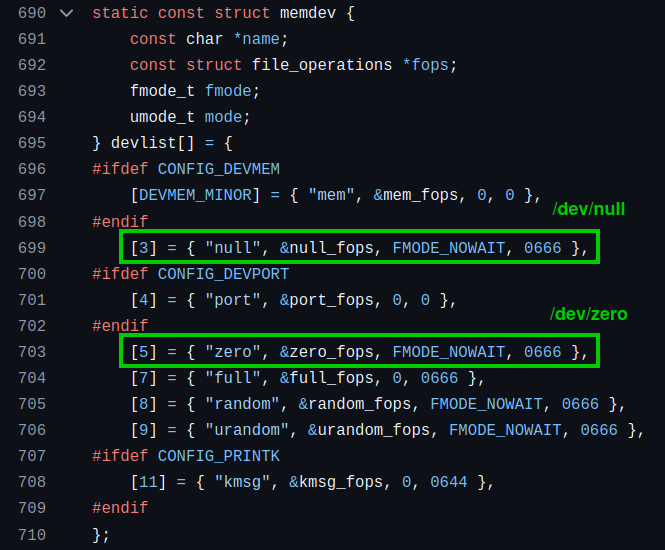
之后,我们可以在 `devlist` 列表中找到这两个设备的定义代码:
而分析 `memdev` 的代码,可以发现:
```c
static const struct memdev {
/* 代表设备的名称 */
const char *name;
/* 代表对该设备展开操作时所对应的函数接口 */
const struct file_operations *fops;
/* 设备的文件访问模式 */
fmode_t fmode;
/* 设备的读写权限 */
umode_t mode;
};
```
而对于 `/dev/null` 与 `/dev/zero`,内核都给予了各个用户、用户组、其它用户组读取数据与写入数据的权限(但是没有允许执行这些数据),同时文件模式均要求 `FMODE_NOWAIT`,即对于这些设备的工作,都要求立即反馈结果。
接下来我们把目光放在 `file_operations` 上面,它代表着一层抽象的接口(对上承接具体的文件系统实现,对下则衔接驱动),摘录部分内容如下:
```c
struct file_operations {
// ...
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
ssize_t (*read_iter) (struct kiocb *, struct iov_iter *);
ssize_t (*write_iter) (struct kiocb *, struct iov_iter *);
// ...
} __randomize_layout;
// 注意:所有的文件系统实现的是一个子集而不一定要求全集,即可以选择全部实现,也可以选择部分实现,只要能够符合要求,即可
```
可以发现,只需要把这些捷克三接口实现出来,结合着上面的内容,我们也可以做出一个自己的设备来,接下来请参考 `/dev/null` 与 `/dev/zero` 的部分对应函数:
```c
/* /dev/null */
static const struct file_operations null_fops = {
.llseek = null_lseek,
.read = read_null,
.write = write_null, // 该函数使得我们在写入 /dev/null 时,只得到写入多少字符
.read_iter = read_iter_null,
.write_iter = write_iter_null,
.splice_write = splice_write_null,
.uring_cmd = uring_cmd_null,
};
/* /dev/zero */
static const struct file_operations zero_fops = {
.llseek = zero_lseek,
.write = write_zero,
.read_iter = read_iter_zero,
.read = read_zero, // 该函数使得我们在读取 /dev/zero 时,一直接收到 '\0'
.write_iter = write_iter_zero,
.splice_read = copy_splice_read,
.splice_write = splice_write_zero,
.mmap = mmap_zero,
.get_unmapped_area = get_unmapped_area_zero,
#ifndef CONFIG_MMU
.mmap_capabilities = zero_mmap_capabilities,
#endif
};
```
而当我们把目光放在他们最为人所知的特性上的时候,理解源代码既可以理解其内涵:
```c
/* 目光先看 /dev/null 的写 */
// 参数分别对应具体的文件设备、用户数据缓冲区、缓冲区大小、坐标与偏移
static ssize_t write_null(struct file *file, const char __user *buf,
size_t count, loff_t *ppos)
{
return count; // 直接返回缓冲区大小,什么都不做
}
```
```c
/* 再看 /dev/zero 的读 */
// 参数分别对应具体的文件设备、用户数据缓冲区、缓冲区大小、坐标与偏
static ssize_t read_zero(struct file *file, char __user *buf,
size_t count, loff_t *ppos)
{
size_t cleared = 0; // 最终生成的 '\0' 字节数目
while (count) {
size_t chunk = min_t(size_t, count, PAGE_SIZE); // 获取当前循环中一个筒的大小
size_t left; // 计算起始字节偏移
left = clear_user(buf + cleared, chunk); // 清空指定用户内存空间中的内存,区域范围即前面的 chunk
// unlikely 的作用参考 《C++关键字之likely和unlikely》
// 是一种 CPU 层面的优化方式
// 这里用于判断清理缓存是否成功,未成功则直接返回错误
// 因为失败可能性小,所以用了 unlikely
if (unlikely(left)) {
cleared += (chunk - left);
if (!cleared)
return -EFAULT;
break;
}
cleared += chunk; // 更新已经清空的字节数目
count -= chunk; // 更新还需要清空的字节数目
// 如果此时信号(软中断)出现,则中止运行
if (signal_pending(current))
break;
// 需要对“抢占点”做一个了解才可以理解,也是一种优化机制
cond_resched();
}
return cleared; // 返回最终生成的 '\0' 字节数目
}
```
这也就为我们理解 Linux 的这两个空设备,提供了有意义的思考与理解,感兴趣的朋友可以顺藤摸瓜,区可去看看其他的实现,那里想必也有着许多有意思的东西。
## 写在最后
目前,我正在加快补习自己在分布式数据库有关的基础知识,相信这将为我们后续回归参与贡献数据库内核生态(存储引擎方向)作下重要的铺垫,感谢陈小伟老师提供的 TinyKV 项目,让我看到了自己在这方面的严重不足,感谢牛世继老师一系列的帮助工作,他严谨的作风以及平和的沟通方式非常值得学习,感谢袁国铭老师、魏波老师、王其达老师、任娇老师与张凯老师、于雨老师、严少安老师、黄宏亮老师、尹海文老师、汤瑞麟老师、符芬菊老师、@Bert、彭冲老师 老师的帮助工作,使得我的职业选择在很早的时候,就有了一个明确的方向。
同时,非常感谢青学会吴洋老师给予的交流平台,期待这份材料可以帮助更多的朋友们减少在这项知识上面的学习时间。