
.png)
OpenTenBase 的安装与使用(失败经验记录)

文一
感谢开放原子开源基金会的张凯老师、符芬菊老师、臧秀涛老师,他们给予的宝贵机会,让我能够直接接触到业界前沿的项目,在自己感兴趣的开源存储引擎上面展开无尽的探索,我们将会继续前进,为建设一个更为开放繁荣的开源基础软件生态而努力。
OpenTenBase 是由开放原子开源基金会与腾讯公司共同建设的一款分布式关系型数据库软件,前身是已经停止维护的 PostgreSQL-XL(对 PostgreSQL 9.2 的一种分布式改造方案),历史关系图如下:

相较于集中式数据库,分布式数据库软件的特点,就在于重视数据的多节点、集群化部署,OpenTenBase 的架构图如下所示:

其中,我们应该注意到:
- 用户直接打交道的数据是协调节点,它将会将用户的指令传递到数据节点上,并自数据节点中提取数据,传递给用户
- 全局有且仅有一个事务管理器,它负责管理集群下的事务号,进而保障数据的一致性(也就是说,同一份数据,在同一阶段,呈现给用户的结果,将会尽力而为地做到一模一样。同时,我们这里必须明确一点,因为在分布式环境下,同一份逻辑上的数据,如表中的某一行,总是存储于一个乃至于多个物理的节点上,因此物理数据的不一致,是一个经常见到的事情(因为各个节点的网络连接速度、修订数据的效率等都往往是不一样的,同时,因为支持并发访问的切实需要,单一节点上面的的事务,采行的是 MVCC 机制,同一份数据维护着多个版本,因此物理数据的一致几乎是不可能),所以我们所维护的数据的一致性,往往指的是逻辑上的一致,而物理数据的一致性,则更多地是一种“可遇不可求”)
- 分布式数据库的连接与访问在用户层面上应当与单机集中式数据库没有显著差异,那些多个节点的工作应当在后台由协调节点、全局事务节点等负责完成
- 架构图里面做了简化,其实每一个类别的节点都是分为主节点(奔赴一线)和备用节点(后方待命)的,这是为了在发生故障时,集群可以很快地恢复到正常状态中,在配置文件里面,备用节点往往有一个
slave后缀
这样,我们就对 OpenTenBase/PostgreSQL-XL 建立了基本的了解,下一步的工作,便在于真正运行起他们来。
下载 OpenTenBase
# 下载 OpenTenBase 源代码包,并将其放置于 OpenTenBase 文件夹
git clone https://atomgit.com/opentenbase/OpenTenBase.git OpenTenBase
安装配套组件
# 假定在 Fedora Linux/RHEL/CentOS 平台下面
sudo yum -y install gcc make readline-devel zlib-devel openssl-devel uuid-devel bison flex git
# 假定在 Debain/Ubuntu 平台下面
sudo apt -y install gcc make readline-devel zlib-devel openssl-devel uuid-devel bison flex git
编译 OpenTenBase
单机实验分布式数据库的话,只需要准备一套编译好的应用程序就行(但是我们需要启动多组服务端程序,让他们挂载在不同的端口上模拟各种节点,并且给出不同的配置数据让他们展现出不同的行为,进而达到“单机模拟分布式”的目的)。

(OpenTenBase 遵循 “Server-Client” 模型)
为了简化编译的流程,欢迎你制作一个编译用的脚本,假定命名为 build_opentenbase.sh,内容如下:
opentenbase_install_path=$HOME
opentenbase_dir_name=opentenbase
# 请确保 OpenTenBase 文件夹与 build_opentenbase.sh 放置于一起
cd OpenTenBase
./configure --prefix=$opentenbase_install_path/$opentenbase_dir_name --enable-debug --enable-profiling --enable-dtrace --enable-cassert CFLAGS="-ggdb -Og -g3 -fno-omit-frame-pointer"
make install
之后,打开 shell,执行 chmod +x build_opentenbase.sh,为脚本添加执行的权限,然后执行:
./build_opentenbase.sh
编译 OpenTenBase,顺利的话,结果如下:
至此,我们已经成功地编译了 OpenTenBase,但是想要真正使用起他们来,还需要我们将配套的环境变量乃至于初始数据准备好。
配置操作系统用户
sudo adduser opentenbase
导入环境变量
在环境变量中引入 OpenTenBase 的路径,有助于简化流程,这里我们可以展开一个对比的工作:
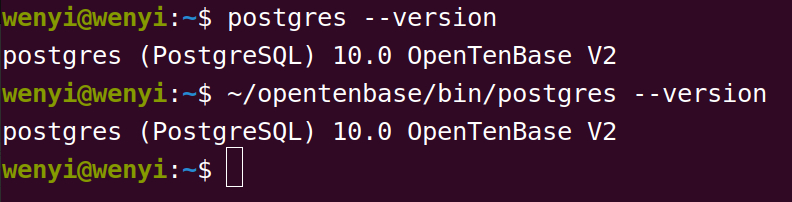
(前者与后者本质上就是一个操作,但是因为我们导入了环境变量,使得 shell 可以搜索找到应用程序,所以我们的工作也简化了不少)
如何实现呢?打开 .bashrc 文件(一般而言,加 . 的文件都是被隐藏了的,所以你需要使用 vim 搜索目录,或者打开系统“查看隐藏文件”选项):
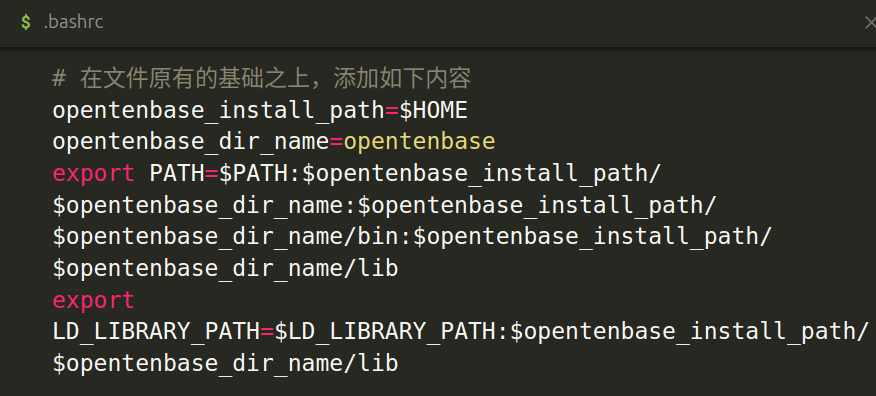
导入如下内容:
# 在文件原有的基础之上,添加如下内容
opentenbase_install_path=$HOME
opentenbase_dir_name=opentenbase
export PATH=$PATH:$opentenbase_install_path/$opentenbase_dir_name:$opentenbase_install_path/$opentenbase_dir_name/bin:$opentenbase_install_path/$opentenbase_dir_name/lib
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$opentenbase_install_path/$opentenbase_dir_name/lib
分类配置节点:Coordinator Node/Data Node
因为我们处于测试的环境下,只有一台机器,因此省略各种节点的 slave 配置步骤(他们是用于故障转移的),因为本机的 ip 地址总是保持一致,因此我们通过端口号来进行区分。
这里,我们可以进行一个简单的思考,相同的代码编译出来的程序,究竟是因为怎样而展现出了不同的行为呢?答案就在于处理的逻辑以及输入的数据不一样,理解这一点,可以帮助你理解后面一系列的针对不同类型的节点的配置行为(同时这也启发了我们:不同节点的身份并非泾渭分明,而是在一定的条件下,能够进行转换)。
但是这里出现了一定的问题,在我们配置 Coordinator/Data 节点的时候,我们发现 OpenTenBase 的 initdb 初始化程序,会提报如下的问题:
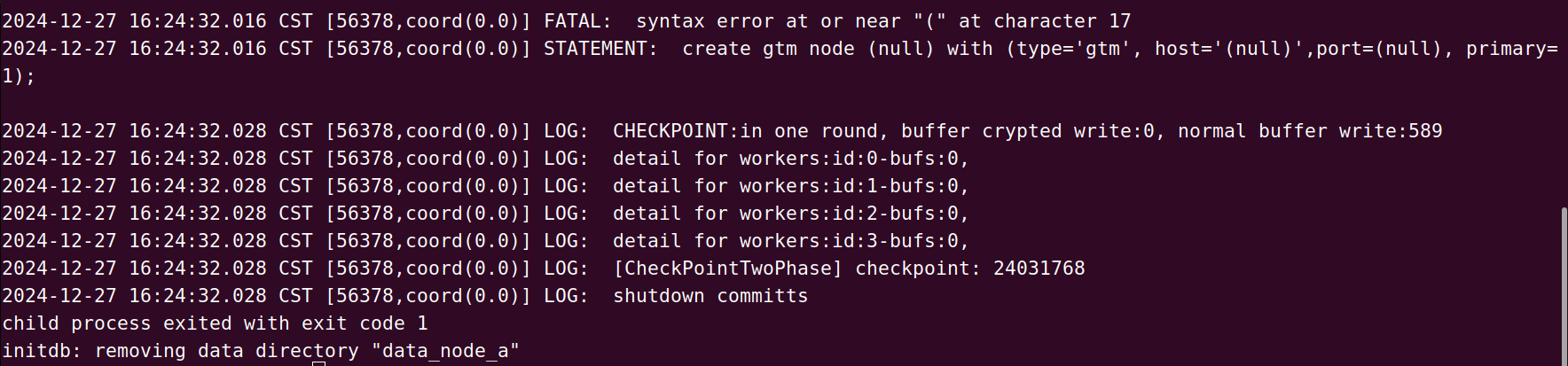
分类配置节点:GTM Node
# 使用 initgtm 初始化目录,假定使用 data_gtm 存储数据
initgtm -D ~/opentenbase/data_gtm -Z gtm
写在最后
尽管这是一次失败的安装经历,但是我们也从中学习到了很多东西,也发掘出了 OpenTenBase 的 Bug,这就足够了,任何时候都要学会说谢谢,这样才可以帮助我们调动一切积极因素展开工作。