

Redis 日志机制简介(二):AOF 日志

文一
Redis 日志机制简介:AOF 日志
只有不断学习,保持开放的的心态,才可以慢慢向着一流的数据库内核专家的方向挺进。
在 Redis 中,AOF 日志承载起了将用户有效输入持久化的职责,可用来指导 Redis 的重启/崩溃后恢复工作。
前置知识
庞大的事物,往往组装于简单的对象,因此我们逐点分析,自然而然就建立了一个对庞大事物的良好理解。
数据的一致性
为数据的存储而构建数据库的一个重要的目的,便在于保障数据的一致性,而什么是数据的一致性呢?即多个事务在并发工作时,每一个事务所使用的数据应当是前后一致的,即不会出现读取到尚未提交的数据(脏读),不会因为其它事务提交修改了数据而使得自身的工作数据出现变化(幻读),不会在事务内出现数据前后不一致的行为(不可重复读),换而言之,数据的一致性指代的就是事务工作时自身数据不受打扰的权利。
注:因为数据库在实际工作时,所应对的数据量,往往很大,而保持极其严格的数据隔离级别(即逐个事务执行的可串行化,完全规避脏读与幻读),往往会使得数据库的数据处理能力下降许多,因此许多工业级数据库喜欢选择较低一些的数据隔离级别,如可重复读(规避了不可重复读、脏读,但是有幻读),已提交读(规避了脏读),用允许一定错误的方式,换来性能的提升
数据库的状态
状态,代指在某个时刻,数据库工作运行时的一系列参数与得出来的运行结果,就如同我们在办公时,出现某种情况不得不离开,因此保存并关闭了我们目前所操作的文档,回来后继续打开文档恢复工作一样,状态往往就代表了那个保存起来的文档,可以使得我们的工作被打断以后,继续恢复执行。

(可以使用操作系统中的任务切换,函数调用中的保存调用现场等场景辅助理解)
而复现程序的工作状态,实际上遵循的逻辑也并不困难,因为我们所有的计算机程序,都遵循 “输入数据 --- 处理数据 --- 输出数据” 的原理,因此,只需要我们给定相同的输入数据,遵循相同的处理流程,基本就可以得出一样的输出数据(这里,请允许我们排除随机数等因素,用以简化问题)。
PostgreSQL, Redis 等数据库的数据恢复,即遵循这一道理。
数据的持久化存储
我们在学习计算机编程的时候,均学习过易失性存储与非易失存储的理念,用到生活之中,便是内存一旦断电,数据即丢失,磁盘即使断电,数据依旧持有。
数据库数据的持久化存储,实际上同样遵循着这样的道理(软件永远是对硬件的锦上添花,它永远不能够违背硬件的原理),它的办法就是把原本存储于内存中的用户输入指令与数据,用一定的办法,组织成为“日志”(即一组数据块),再将其存储于磁盘等非易失存储上,最终再按照需要将其提取出来,即是如此。
数据的快照
数据快照便是用一定的方式,存储某个工作节点的程序运行状态的一种策略,如在 PostgreSQL 中,数据快照的存储结构描述如下:
/*
PostgreSQL 快照类型的划分,可以分为普通的基于 MVCC 机制的快照,用于故障恢复的快照,逻辑解码期间的快照,传递给 HeapTupleSatisfiesDirty() 快照, 传递给 HeapTupleSatisfiesNonVacuumable() 的快照,用于 SatisfiesAny, Toast 等机制的快照。
*/
typedef struct SnapshotData
{
SnapshotType snapshot_type; /* 标识快照的类型 */
/* 事务 ID 的 (xmin, xmax) 代表该快照的有效作用范围 */
/* xid 就是逻辑意义上的时间划分,已经过去的事情我们都知道,而尚未发生的事情我们是不知道的,而每一个事务和快照都有着不同的 xid,这是因为他们在不同的时间点由不同用户发起 */
/* 更为具体的需要结合隔离级别的有关知识去加以理解 */
TransactionId xmin; /* XID < xmin 则可见,代表过去发生的操作 */
TransactionId xmax; /* XID >= xmax 不可见,代表尚未发生的操作 */
/* 存储正在运行中的事务 ID/已经提交的事务 ID */
/* xmin <= xip[i] < xmax */
TransactionId *xip;
/* 存储了多少事务 ID */
uint32 xcnt;
/* 存储子事务 ID(运行时) */
TransactionId *subxip;
/* 存储了多少子事务 ID */
int32 subxcnt;
/* 是否超载? */
bool suboverflowed;
/* 是否被用于故障恢复? */
bool takenDuringRecovery;
/* 是否为静态快照,为 false 时,则是 */
bool copied;
/* 当前快照所对应的指令 ID */
CommandId curcid;
/* 为 HeapTupleSatisfiesDirty() 准备的额外内容,同 MVCC 无关 */
uint32 speculativeToken;
/* 用于决定可以被 Vacuum 的数据行 */
struct GlobalVisState *vistest;
/* 为快照管理器准备的信息 */
uint32 active_count;
uint32 regd_count;
pairingheap_node ph_node;
/* 快照被记录下来的时间,此处是物理时间而不是逻辑时间 */
TimestampTz whenTaken;
/* 快照所对应的 Wal 日志位置 */
/* 注意:快照内部并不包含任何物理数据,它实际上便是对事务运行时状态以及 wal 日志模块状态的一个二次记录,这块在一开始确实容易让人产生混淆 */
XLogRecPtr lsn;
/* 使用 GetSnapshotData() 构建快照时的事务完成计数, 这样就可以规避重复设计静态快照浪费资源的问题 */
uint64 snapXactCompletionCount;
} SnapshotData;
而在执行查询语句的时候,请参考如下:
而 PostgreSQL 的 SnapShot,实际上被组织为栈的方式,参考如下:

(这就和 int *array 这种组织方式是一个原理,区别只在于数据类型的不同,而术语方面都用的是 pop 与 push,基本上只需要建立一个简单的对于栈的理解,就可以理解 PostgreSQL 栈的组织方式)


而导出快照的时候,则参考为如下:
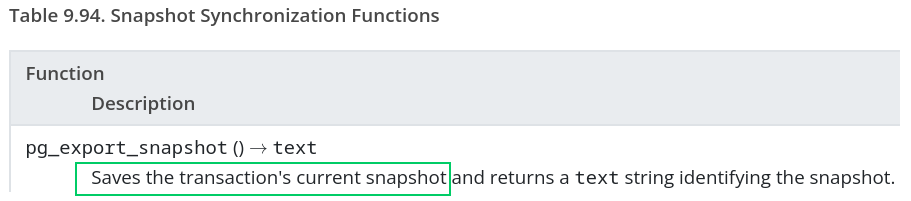
(PostgreSQL 用于导出快照的函数)

(原理:先获取栈顶的快照,再结合当前上下文环境做导出)

(一些具体的代码,用以辅助理解,MyProcPid 代表着当前场景下面的 PID)
在有了这个基础之上,我们也就具备了了解 Redis AOF 日志的能力,参考下面的内容。
Redis AOF 日志的组成
自注释上面看,AOF 日志由下面的三个部分组成:
/*
BASE(基准点): 代表自上一次 AOF 重写以后的 Redis snapshot, 一则 AOF 日志中最多包含一个单独的 Base 文件,它也将是序列中的第一对象
INCR(追加的指令):代表最后一次成功地重写后追加进入的 Redis 写入指令,在部分场景下面,可能会有多种不同的顺序
HISTORY(历史):在成功地重写工作展开以后,所有的 BASE, INCR 部分即转变为 HISTORY 文件,并会在一定情况下被删除(除非垃圾回收机制被禁止)
*/
/* 对应的文件后缀名 */
#define BASE_FILE_SUFFIX ".base"
#define INCR_FILE_SUFFIX ".incr"
#define AOF_FORMAT_SUFFIX ".aof"
对应的标识如下所示:
typedef enum {
AOF_FILE_TYPE_BASE = 'b', /* BASE 文件 */
AOF_FILE_TYPE_HIST = 'h', /* HISTORY 文件 */
AOF_FILE_TYPE_INCR = 'i', /* INCR 文件 */
} aof_file_type;
/* 将庞大的数据切分成一个个数据块是一种非常常见的做法 */
typedef struct {
sds file_name; /* 文件名称 */
long long file_seq; /* 文件序列号 */
aof_file_type file_type; /* 文件类型 */
} aofInfo;
最终集成为一个如下的结构:
typedef struct {
/* BASE 文件 */
aofInfo *base_aof_info;
/* INCR 文件,重写失败时可能有多个 */
list *incr_aof_list;
/* 历史文件,重写成功的时候,包含着先前的 `base_aof_info` 与 `incr_aof_list` 两个部分,整个流程完成后,他们会被删除 */
list *history_aof_list;
/* 当前 BASE 文件使用的序列号. */
long long curr_base_file_seq;
/* 当前 INCR 文件使用的序列号 */
long long curr_incr_file_seq;
/* 1 代表我们需要将内存中的这个部分同磁盘上做同步 */
int dirty;
} aofManifest;
对于 BASE 文件,我们在前面的文章中,已经建立了基本的认识,因此,现在我们将目光着眼于 INCR 之上,这里就需要联系到 rewrite 的概念,参考下面的内容:
Redis Rewrite 是什么?
在 Redis 文档 https://redis.io/docs/latest/operate/oss_and_stack/management/persistence/ 中,Rewrite 被定义为:
伴随着数据写入操作的进行,AOF 日志变得越来越大。举例来说,当你累积写入100次以后,你最终的数据集合中只会有你最后写入的数据以及对应的数据键。但是在你的 AOF 文件中,将会存在有100条对应的记录。而这些记录中的99条对于构建当前的运行状态来说,都毫无意义。
因此,Redis 支持一项非常有意思的特性:它能够在不打断客户端与服务端服务的情况下,重新构建 AOF 日志文件。无论何时,只要你执行了 BGREWRITEOF 指令,Redis 将会构建一个对于当前数据集合而言,最短的数据指令集合。
言归正传,这些操作便是针对于 INCR 部分而展开,因为就在这一个部分里面,Redis 记录了所有追加的指令。
因此,请让我们把眼光放在 rewriteAppendOnlyFile 上,它是实现这项功能的重要支撑:
/* 限制于篇幅,进行了精简的工作 */
int rewriteAppendOnlyFile(char *filename) {
rio aof;
FILE *fp = NULL;
char tmpfile[256];
/* 结合 PID 创建临时 AOF 文件 */
snprintf(tmpfile,256,"temp-rewriteaof-%d.aof", (int) getpid());
fp = fopen(tmpfile,"w");
if (!fp) {
/* 创建失败则宣告结束 */
return C_ERR;
}
/*
关于 RIO 的具体内涵,请参考《深入理解计算机》中
“用 RIO 包健壮地读写” 的一部分,Redis 的实现实际上是它的变体
https://hansimov.gitbook.io/csapp/part3/ch10-system-level-io/10.5-robust-reading-and-writing-with-the-rio-package
*/
rioInitWithFile(&aof,fp);
if (server.aof_rewrite_incremental_fsync) {
rioSetAutoSync(&aof,REDIS_AUTOSYNC_BYTES);
rioSetReclaimCache(&aof,1);
}
startSaving(RDBFLAGS_AOF_PREAMBLE);
/* 核心代码 */
if (server.aof_use_rdb_preamble) {
int error;
if (rdbSaveRio(SLAVE_REQ_NONE,&aof,&error,RDBFLAGS_AOF_PREAMBLE,NULL) == C_ERR) {
errno = error;
goto werr;
}
} else {
if (rewriteAppendOnlyFileRio(&aof) == C_ERR) goto werr;
}
/* 将缓冲区内的内容直接同步到磁盘 */
if (fflush(fp)) goto werr;
if (fsync(fileno(fp))) goto werr;
if (reclaimFilePageCache(fileno(fp), 0, 0) == -1) {
/* A minor error. Just log to know what happens */
serverLog(LL_NOTICE,"Unable to reclaim page cache: %s", strerror(errno));
}
if (fclose(fp)) { fp = NULL; goto werr; }
fp = NULL;
/* 完成写入工作,迁移文件 */
if (rename(tmpfile,filename) == -1) {
/* ... */
return C_ERR;
}
stopSaving(1);
return C_OK;
werr:
/* 发生错误时,在服务器日志中记录,并且移除临时文件,结束工作流程 */
/* ... */
return C_ERR;
}
之后,让我们将眼光放在 rewriteAppendOnlyFileRio 上,它是 Redis 精简流程的核心:
int rewriteAppendOnlyFileRio(rio *aof) {
dictEntry *de;
int j;
long key_count = 0;
long long updated_time = 0;
kvstoreIterator *kvs_it = NULL;
/* 记录重写 AOF 日志的时间,并记录下来 */
if (server.aof_timestamp_enabled) {
/* ... */
}
/* 如果重写 Lua 函数出现错误,结束工作 */
if (rewriteFunctions(aof) == 0) goto werr;
/* 开始遍历 Redis Database, 逐个保存指令 */
for (j = 0; j < server.dbnum; j++) {
char selectcmd[] = "*2\r\n$6\r\nSELECT\r\n";
redisDb *db = server.db + j;
if (kvstoreSize(db->keys) == 0) continue;
/* 切换至新的 Database */
if (rioWrite(aof,selectcmd,sizeof(selectcmd)-1) == 0) goto werr;
if (rioWriteBulkLongLong(aof,j) == 0) goto werr;
kvs_it = kvstoreIteratorInit(db->keys);
/* Iterate this DB writing every entry */
while((de = kvstoreIteratorNext(kvs_it)) != NULL) {
sds keystr;
robj key, *o;
long long expiretime;
size_t aof_bytes_before_key = aof->processed_bytes;
keystr = dictGetKey(de);
o = dictGetVal(de);
initStaticStringObject(key,keystr);
expiretime = getExpire(db,&key);
/* 分类处理各类对象... */
/* 尝试削减占用的资源... */
/* 尝试存储过期时间... */
if (expiretime != -1) {
/* ... */
}
/* 每1024个键以后,更新一次信息 */
if ((key_count++ & 1023) == 0) {
/* ... */
}
/* 出于测试目的,每一次停留一段时间 */
if (server.rdb_key_save_delay)
debugDelay(server.rdb_key_save_delay);
}
kvstoreIteratorRelease(kvs_it);
}
return C_OK;
werr:
if (kvs_it) kvstoreIteratorRelease(kvs_it);
return C_ERR;
}
这里,我们继续以 SET 这种对象为案例,深入理解这一流程:
int rewriteSetObject(rio *r, robj *key, robj *o) {
long long count = 0, items = setTypeSize(o);
setTypeIterator *si = setTypeInitIterator(o);
char *str;
size_t len;
int64_t llval;
/* 逐个遍历 SET 对象 */
while (setTypeNext(si, &str, &len, &llval) != -1) {
if (count == 0) {
/* 将多个合并为一个 */
int cmd_items = (items > AOF_REWRITE_ITEMS_PER_CMD) ?
AOF_REWRITE_ITEMS_PER_CMD : items;
/* 请参考 Redis 协议的有关部分 */
if (!rioWriteBulkCount(r,'*',2+cmd_items) ||
!rioWriteBulkString(r,"SADD",4) ||
!rioWriteBulkObject(r,key))
{
setTypeReleaseIterator(si);
return 0;
}
}
/* 写入到文件之中 */
size_t written = str ?
rioWriteBulkString(r, str, len) : rioWriteBulkLongLong(r, llval);
if (!written) {
setTypeReleaseIterator(si);
return 0;
}
if (++count == AOF_REWRITE_ITEMS_PER_CMD) count = 0;
items--;
}
setTypeReleaseIterator(si);
return 1;
}
同时,对于 kvstore,我们摘录 kvstore.c 中的一段注释,供大家理解:
/*
基于索引的 KV 存储实现,它实现了由一组字典组成的 kv 存储(请参考 dict.c)
目的在于使得归属于同一字典的全部数据键变得容易
*/
而 dict.c,实际上便是一种动态哈希表的实现方案,关于动态哈希表,我所撰写的 PostgreSQL 的一篇文章 浅谈 PostgreSQL 动态哈希表 可以用来帮助理解。
Redis AOF 的具体工作函数
Redis AOF 因为涉及的数据类型,数据处理函数等,均是一个不一样的状态,因此,Redis 采行了分类处理的办法,如图所示


Redis 的处理函数,实际上便是将其交付给不同的函数指针处理,由此来展开一个压缩的工作。
其它的诸多函数如 getAppendOnlyFileSize 等,不过是锦上添花,关键的部分,还是在于分类处理,真正做到压缩数据量。
写在最后
感谢一路上指导我的老师们,我们将继续提升建设水平,力争建成一个繁荣的数据库内核生态。